How To Find Mode If There Is No Repeating Numbers

Okay, so picture this: I’m at my cousin Brenda’s birthday bash, right? Brenda, bless her cotton socks, is super into organizing. Like, color-coded everything, a spreadsheet for the guest list that would make an accountant weep with joy, the whole nine yards. This year, she decides she wants to do a “stats” theme for the party favors. I kid you not. We’re talking little miniature rulers, tiny protractors, and some frankly baffling graphs printed on coasters.
And then there was the party favor distribution. Brenda, naturally, had a system. She’d lined up all the goodie bags and, with the precision of a brain surgeon, handed them out one by one. After everyone had nabbed their little parcel of statistical joy, Brenda, with a triumphant flourish, pulls out a sheet of paper and declares, “Alright everyone, let’s see the most popular favor!”
Everyone leans in, eager to see what the crowd gravitated towards. But then… a collective… hmmmmm. Brenda’s brow furrows. She squints at her little tally marks. “That’s… odd,” she mutters. “Everyone got one of each item. There’s no… most popular item.”
Silence. The statisticians in the room (me, and maybe Brenda’s cat who was eyeing a stray party hat) looked at each other, bewildered. How can there be a "most popular" thing if everyone got the same amount of everything? It felt like trying to find the tallest ant in a colony where all ants are exactly the same height. Utterly perplexing.
This, my friends, is where we bump into a little statistical conundrum: what do you do when the very concept of "most frequent" seems to… disappear?
The Ghost of the Mode: When No Number Wants to Stand Out
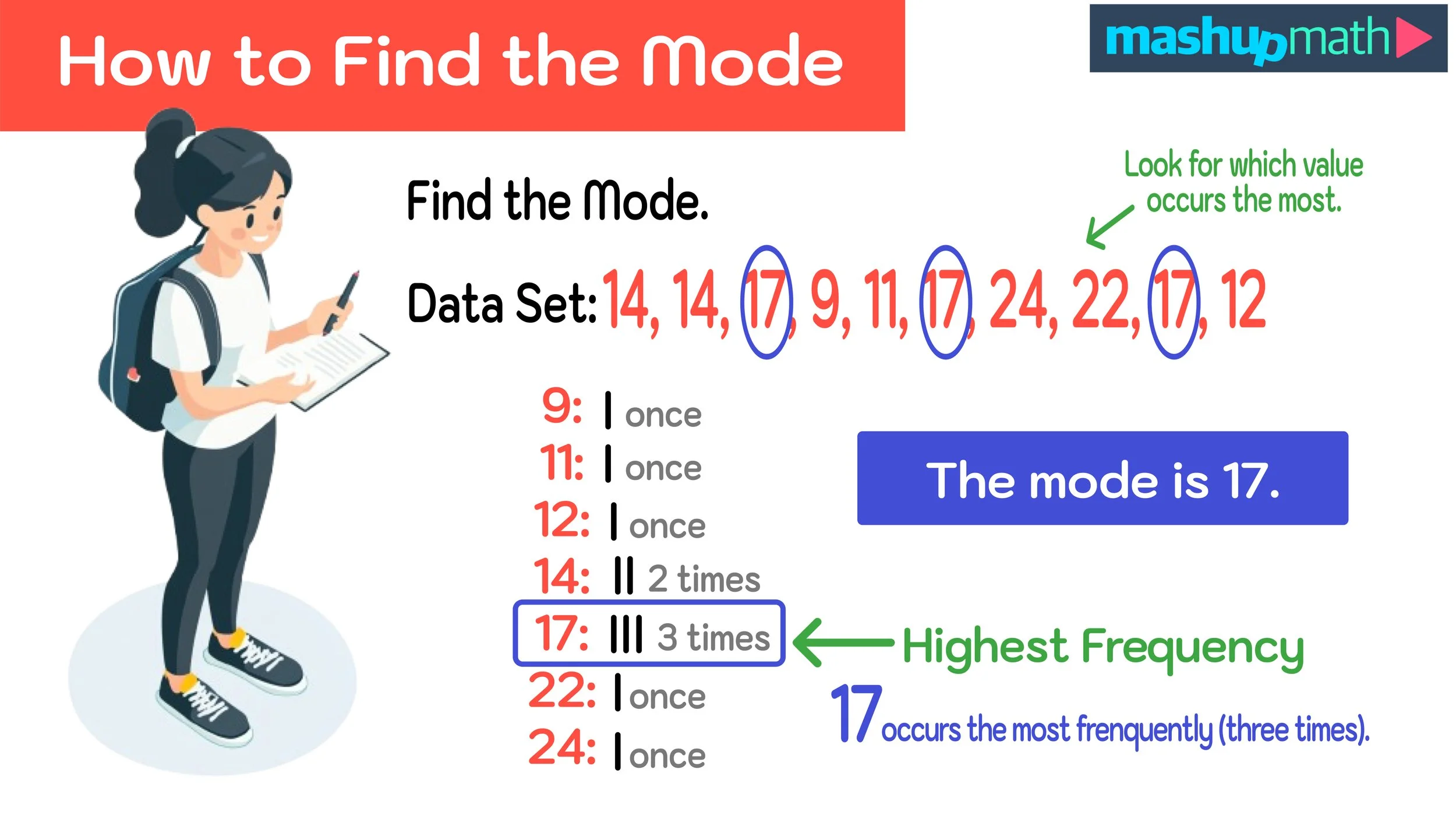
So, you’ve probably heard of the mode. It’s that number in a set of data that shows up the most. Easy peasy, right? Like if you ask a bunch of people their favorite ice cream flavor and “chocolate” pops up five times, while “vanilla” only shows up twice, and “strawberry” once, then chocolate is your clear winner, your reigning monarch of deliciousness. Your mode.
But what happens when you’re staring at a list of numbers, and… crickets? No number is repeating. Every single one is unique. Like the party favors Brenda meticulously organized, where every bag contained the exact same assortment of statistically themed trinkets. It’s a statistical flatline. A data desert. A… well, you get the idea.
It’s enough to make you want to throw your calculator out the window, isn’t it? You’re staring at your homework, or a work report, or maybe you’re just trying to figure out which sock color is the most represented in your laundry pile (a surprisingly common statistical query, I’ve found), and there’s just… nothing. No repeats. No champions. No mode.
So, What’s a Data Detective to Do?
Here’s the thing, and it might sound a little anticlimactic, but it’s also kind of liberating: If there are no repeating numbers in your dataset, then there is technically no mode.
Yep. That’s it. You heard me. No mode. Nada. Zilch. It’s like asking who the loudest person in a library is. They’re all supposed to be quiet, remember? The premise itself is flawed.
Think about it. The mode, by definition, is about frequency. It’s about that one guy who really loves wearing a certain color, or that one movie that everyone seems to have seen. If everyone is wearing a different color, or if everyone has seen a completely unique movie, then there’s no single standout.
So, when you’re faced with this situation, don’t panic. Don’t start inventing numbers or arbitrarily declaring a winner. Just… state the facts. “In this dataset, there are no repeating values, therefore there is no mode.”
It feels a bit like a magic trick where the magician makes something not appear. But it’s honest statistics. And in the world of numbers, honesty is usually the best policy. Unless you’re trying to convince your kids that broccoli is actually a delicious treat, in which case, a little creative license might be necessary. But for statistics? Stick to the truth.
But Wait, There’s More! (Or, How to Deal with the "All Numbers Are Unique" Crisis)
Now, while technically there’s no mode, that doesn’t mean your data is completely uninteresting or that you can’t glean any insights from it. You just have to shift your focus, my data-crunching comrades.
-Step-7.jpg)
What you do have is a dataset where every single data point is equally “frequent” in its uniqueness. It’s a peculiar kind of uniformity. It means that in terms of repetition, everything is on the same playing field. Or, more accurately, off the playing field entirely.
Consider the Big Picture: Mean and Median
If the mode is playing hide-and-seek and refusing to be found, you still have other statistical tools in your arsenal. The mean (that’s your average, the sum of all numbers divided by how many numbers there are) and the median (the middle number when your data is sorted) are still very much alive and kicking.
These measures of central tendency can give you a sense of the “typical” value in your dataset, even if no single value is the most common. For example, if you’re looking at the heights of a group of people and everyone is a different height, the mean height will tell you the average height, and the median height will tell you the height of the person smack-dab in the middle.
So, while the mode might be AWOL, don’t let that stop you from exploring what your data is telling you. It’s like having a detective team, and the "mode detective" is on vacation. You’ve still got the "mean detective" and the "median detective" ready to solve the case!
When Every Number is the Mode? (Yes, it’s a Thing!)
Now, let’s add a little twist to this. What if you do have repeating numbers, but… all of them repeat? And they repeat the same number of times? This is where things get a bit more nuanced, and frankly, a lot more interesting.
Imagine you surveyed people about their favorite color, and you got these results: * Red: 2 people * Blue: 2 people * Green: 2 people * Yellow: 2 people
In this scenario, you have four different numbers (Red, Blue, Green, Yellow) that all appear with the same highest frequency. In this case, you have what’s called a multimodal distribution.

So, if you have multiple numbers that share the highest frequency, then all of those numbers are considered modes. It's not a case of "no mode"; it's a case of "multiple modes"! This is called being bimodal if there are two modes, trimodal if there are three, and so on. If every single data point is unique, that’s when there’s no mode. But if several distinct values are tied for being the most frequent, they all get to wear the crown.
It’s like a popularity contest where there’s a four-way tie for first place. Everyone’s a winner! And in statistics, we celebrate all the winners. We just need to be clear about who they are and how many there are.
Why Does This Even Matter?
You might be thinking, “Okay, this is fascinating, but why should I care about the nitty-gritty of finding a mode when there isn’t one?” Great question! It’s all about understanding the shape and characteristics of your data.
The presence or absence of a mode, and how many modes there are, tells you something about the distribution of your data. * A single, clear mode often suggests a dataset where one particular value or category is significantly more common than others. Think of test scores where most students fall within a certain range. * No mode (because all values are unique) suggests a dataset where there’s a lot of variation, and no single value is standing out. This can happen with continuous data like measurements, or in situations where randomness plays a big role. * Multiple modes indicate that your data has distinct clusters or peaks. This can be super insightful! For example, if you’re looking at the heights of people and find two distinct modes, it might suggest you’re actually measuring two different groups (like adults and children, or men and women if their height distributions differ significantly).
So, while Brenda’s party favor situation was a bit of a humorous illustration, the underlying principle is valid. Understanding when a statistical measure applies and when it doesn’t is crucial for accurate interpretation. It’s about not forcing a square peg into a round hole, statistically speaking.
A Little More Anecdotal Evidence (Because Why Not?)
I remember once helping a friend analyze the results of a survey about their favorite pizza toppings. The list was… eclectic. We had everything from "anchovies" (yes, some people like those salty little devils) to "artichoke hearts" to "pineapple" (don’t even get me started). When we tallied it up, every single topping had been chosen by exactly one person.

My friend looked crestfallen. “So… there’s no favorite pizza topping?”
I had to explain the concept to them. “Well,” I said, channeling my inner statistics professor (which, admittedly, is a rare and sometimes terrifying persona), “technically, there’s no mode. Everyone has their own unique favorite, which is kind of cool in its own way, right? It means your friends have wonderfully diverse pizza palates!”
They ended up deciding that their "most popular" topping was actually a tie between the two toppings that generated the most discussion – pineapple and anchovies. It wasn’t a statistical mode, but it was a thematic one, and for their quirky group, it worked. Sometimes, you have to get a little creative with your interpretations, but it’s important to know when you’re stepping outside the strict mathematical definition.
The Takeaway: Don’t Fear the "No Mode"
So, to wrap this up, if you’re staring down a dataset and every number is playing the lone wolf, don’t sweat it. The absence of a mode is not a failure of your data; it’s a characteristic of your data. It means that, in terms of frequency, every single observation is an individual.
Embrace the uniqueness! Your data might be more spread out, or it might be reflecting a situation where individuality is the norm. Use your other statistical tools – the mean and the median – to get a sense of the central tendency. And if you find yourself with multiple numbers tied for the highest frequency, then congratulations, you’ve got a multimodal dataset on your hands!
Just remember Brenda and her perfectly organized, yet mode-less, party favors. Sometimes, the most interesting statistical finding is that there isn't one. And that, my friends, is perfectly okay. Now, if you’ll excuse me, I’m off to find out the mode of my sock drawer. Wish me luck!